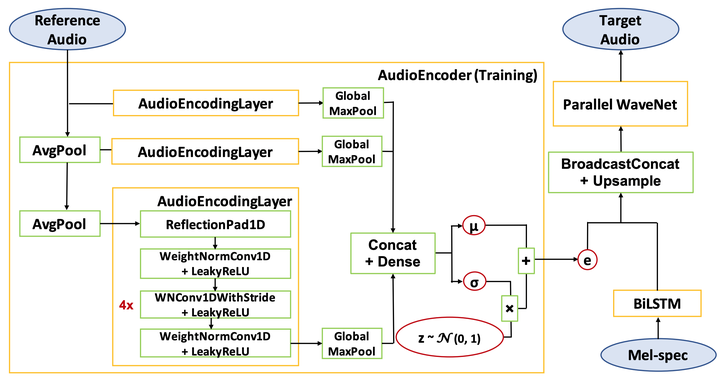
 Universal Parallel WaveNet with an additional VAE-type conditioning network called Audio Encoder.
Universal Parallel WaveNet with an additional VAE-type conditioning network called Audio Encoder.
Abstract
We present a universal neural vocoder based on Parallel WaveNet, with an additional conditioning network called Audio Encoder. Our universal vocoder offers real-time high-quality speech synthesis on a wide range of use cases. We tested it on 43 internal speakers of diverse age and gender, speaking 20 languages in 17 unique styles, of which 7 voices and 5 styles were not exposed during training. We show that the proposed universal vocoder significantly outperforms speaker-dependent vocoders overall. We also show that the proposed vocoder outperforms several existing neural vocoder architectures in terms of naturalness and universality. These findings are consistent when we further test on more than 300 open-source voices.
Yunlong Jiao
Applied Machine Learning Research
My research interests include Deep Generative Models, Vision Language Models, Natural Language Processing, and Computational Biology.